
NLP - Vanilla Transformer
Motives for composing this article was based on attending in a BW Start-up, who mainly focused on AI music transcription. Plus got a ML Job Interview which has NLP as a “shot in the head” in its description. Thus all these circumstances stress me out and i want to get myself somewhat prepared.
Development of NLP
This article provided detailed history of NLP development in academic world. From Word2Vec - CNN based method - RNN based method(LSTM,GRU,Bi-LSTM,Seq2Seq) till recent Attention-based method(transformer) and the SoTA of transformer-based method(BERT,GPT). Despite of hearing some names and seeing some pictures of their architectures in the lecture/Vorlesung, i had barely any idea what do they really do, what are they capable of and how are they implemented.
Bi-LSTM and Seq2Seq
Although Vanilla Transformer is the main character in this show, i still want to document the treasure of my findings today.
As explained, li means the upper context, ri means the lower context and ci is the total context. How is it coded?
I assume that we got 2 layers of LSTM, one for upper context and another for lower context and combined the 2 hidden context together.
Seq2Seq has a form of Enocder(one RNN) and Decoder(another RNN), whilst the connection between is based on a hidden context c. So frankly the model can be interpreted as Seq2Context2Seq
A drawback of Seq2Seq appears when irrelevant information is forced to be encoded into Encoder-Decoder Network, which disturbs the target/objective. We cannot selectively choose input information. Hence Attention is needed.
Vanilla Transformer
Though there are pics with better quality, i like this one because it dissects the architecture straightforwardly. 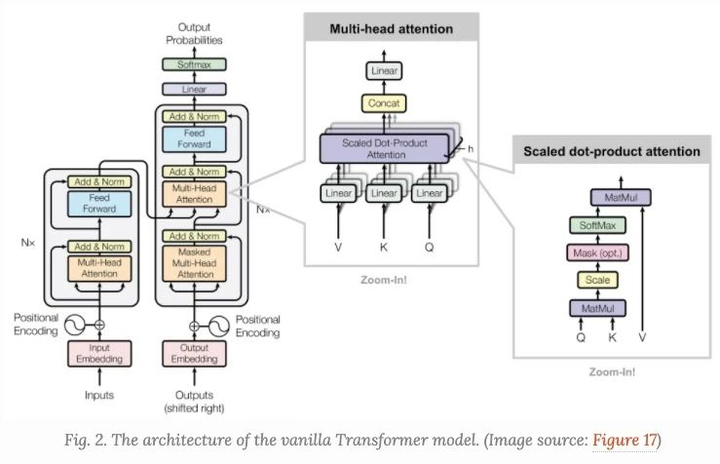 .
. 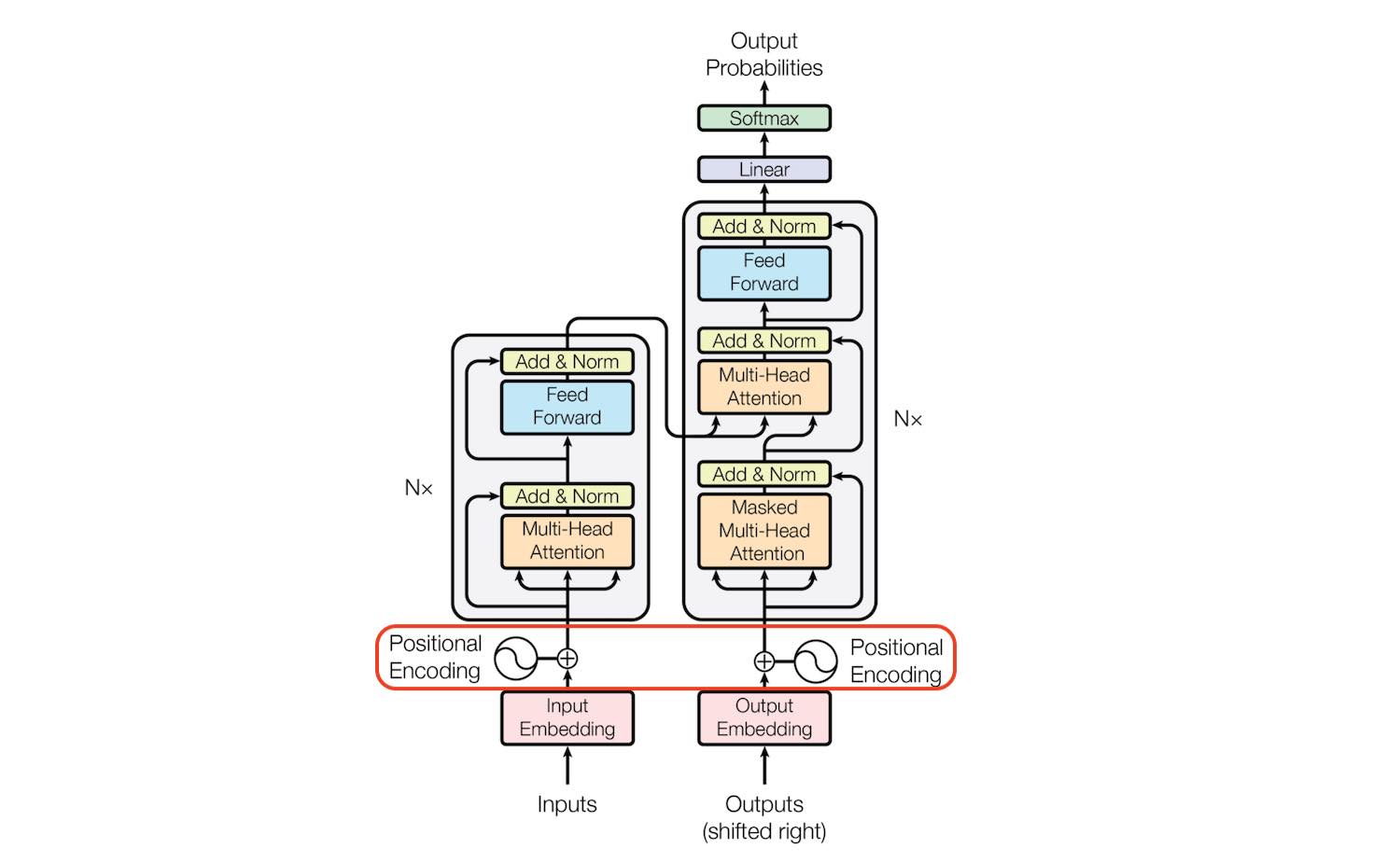 .
.
The target of network is to maximize the probability of predicting the next word correctly. Important sections of vanilla Transformer are listed below:
- Input Embedding Word to Vec, can be simply one-hot encoding of all words or leveraging FastText/Word2Vec to classify words.
- Positional Encoding
This article described the positional encoding very throughly, which i recommend to read. In short, positional encoding answers the questions of where a word/token is located in a sentence and how we can mark it?
- Either we do it ephemerally which is give each token an increasing number from 1 till length of sentence. But it has 2 drawbacks: dimension dilemma and no fixed sentence length.
- Sinuous encoding. The inituition comes from the binary encoding, where the sequence of number is encoded using also a similar techniques.
- Multi-head Attention
Always start from the fine-grained part of a system, so before talk about multi-head, first let us look at single-head attention.
- Attention is in NLP world the weight that needs to be placed on each token/world embedding. There are couple of techniques derived from the basic Query-key-value methodology, let us first look at the primitive one.
- Query Key Value
This answer makes a good analogy: the query(string we type in search bar of youtube), Key(the unique identifier attached to each video) and the Value(the video resource).
- for better formal word explanation, this [wiki](https://en.wikipedia.org/wiki/Transformer_(machine_learning_model) helps a lot.
- It says the query Wq,key Wk,value Wv weights are to be learned.
- root of dk is for stabilizing gradients during training
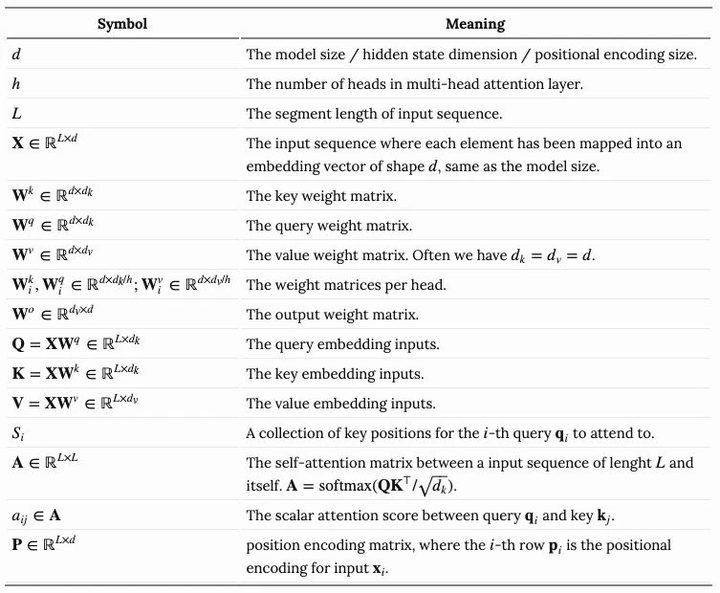
- Overview of all mathematical symbols can be found here.
- Query Key Value
This answer makes a good analogy: the query(string we type in search bar of youtube), Key(the unique identifier attached to each video) and the Value(the video resource).
- Attention is in NLP world the weight that needs to be placed on each token/world embedding. There are couple of techniques derived from the basic Query-key-value methodology, let us first look at the primitive one.
- Multi-head Attention
- For ssame input, we can have multiple attention mechanisms for defining and extracting different word relevance in between. Technically, the final output is concatenation of multiple Attentions then scale-dot it with Multi-head Weight Wo(the linear)
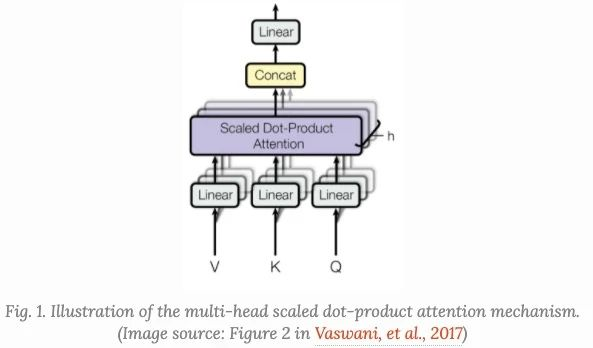
- For ssame input, we can have multiple attention mechanisms for defining and extracting different word relevance in between. Technically, the final output is concatenation of multiple Attentions then scale-dot it with Multi-head Weight Wo(the linear)
- Masked Multi-head Attention(Decoder)
- Masked simply means from my understanding set 0 in corresponding places of Multi-head Weight Wo, which lets the decoder Attenion layer doesn’t has future information.

- Masked simply means from my understanding set 0 in corresponding places of Multi-head Weight Wo, which lets the decoder Attenion layer doesn’t has future information.
- Input & Output
- We have 2 inputs: encoder and decoder inputs. Input of Decoder: Ouputs(shifted right) means the output(current prediction of next word) is the input in Decoder of next time step.
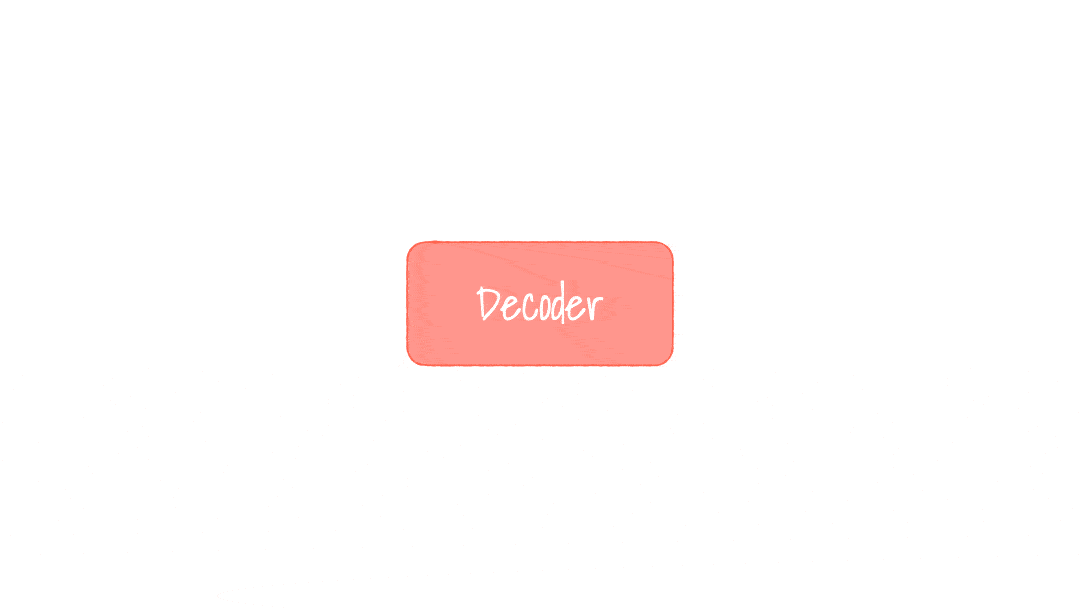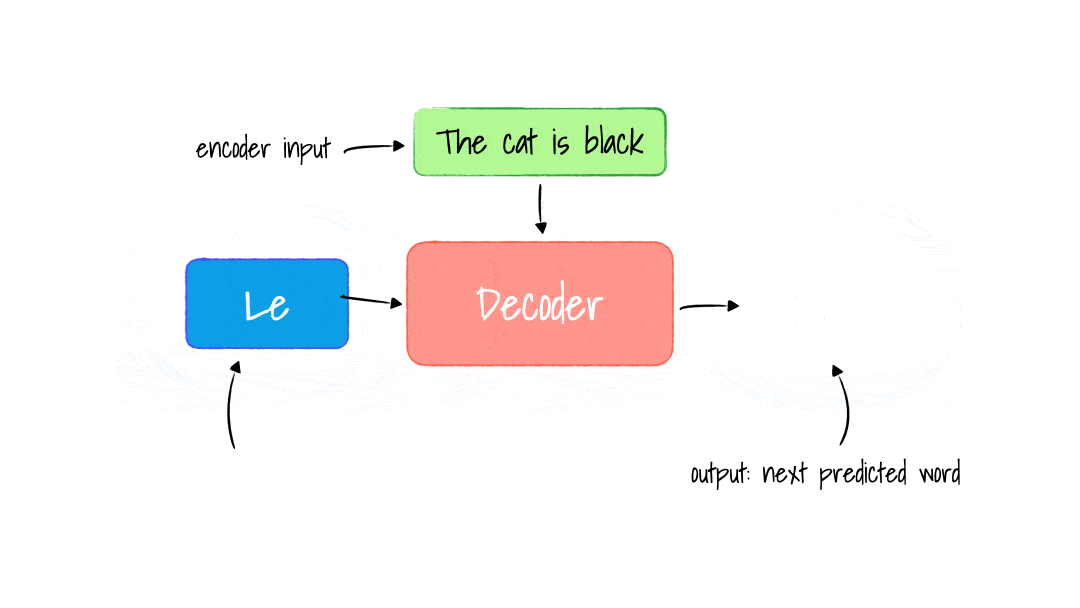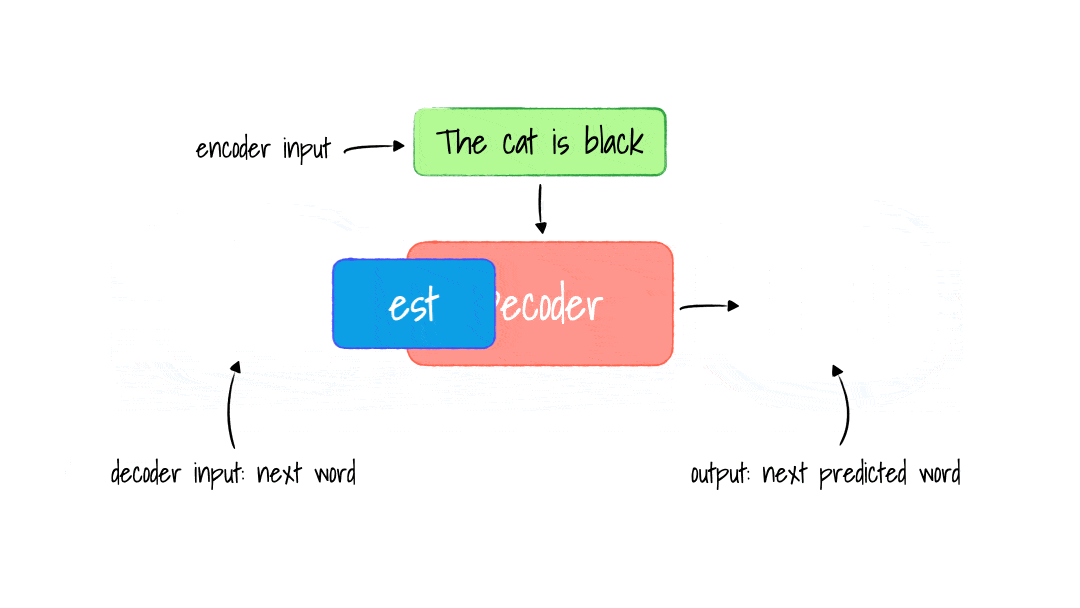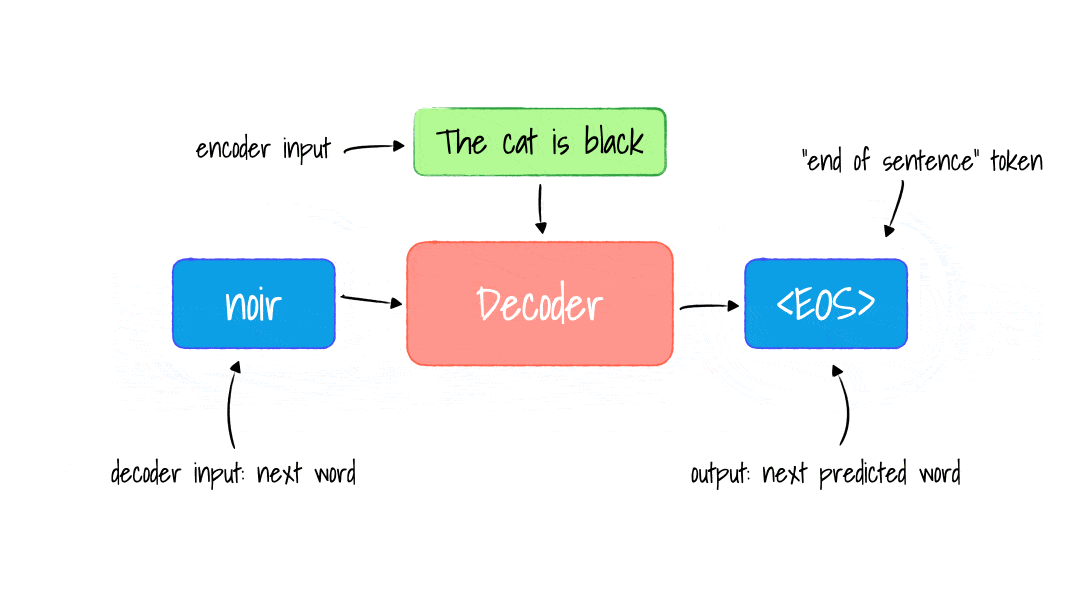
- We have 2 inputs: encoder and decoder inputs. Input of Decoder: Ouputs(shifted right) means the output(current prediction of next word) is the input in Decoder of next time step.
- Pre-training
- No-label generative pretraining is an unspervised training, which is the first step of training GPT, the second step is fine-tuning for differentr tasks: classification, Entailment(A sentence includes B?) Similarity, Multiple choices etc.